
Widespread use of Artificial Intelligence (AI) technologies in FSOs and financial crime risk management systems has encouraged debate around the ethical challenges and risks AI-based technology pose. AI technologies have significant impact on the development of humanity, and so they have raised fundamental questions about what we should do with these systems, what the systems themselves should do, what risks are potentially involved, and how we can control these.
As AI advances, one critical issue remains: how to address the ethical and moral challenges associated with its applications.
Financial services organizations (FSOs) play a central role in the financial wellbeing of individuals, communities, and businesses. In the world of financial services, banks are reshaping their business models increasingly using AI to automate and optimize operations for a wide range of systems and functions. AI is revolutionizing the financial services industry and AI tools are being deployed across the bank, from the customer front end to deep in the back office. AI is used to more efficiently detect suspicious transactions and detect money laundering, to play a powerful role in credit risk assessments, or to more effectively improve the customer experience.
With the ability to ingest and analyze vast volumes of data, AI technology has the capacity to help FSOs better understand their customers, gain insights and identify fraud or security violations more quickly and efficiently. While AI technology promises to help simplify and improve services, companies make decisions that have a significant impact on people, such as approving or withholding credit, foreclosing on a mortgage, or deciding whether to pay out a life insurance claim. At the level of an individual company, these are serious responsibilities—and in aggregate can have major impact on economies and nations.
With the desire to create the best-performing AI models, many organizations have prioritized operational and execution factors over the concepts of explainability and trust. As the world becomes more dependent on algorithms for making a wide range of decisions, technologies and business leaders will be tasked with explaining how a model selected its outcome. Complex AI algorithms allow organizations to unlock insights from data that were previously unattainable. However, the black-box nature of these systems means it isn’t straightforward for business users to understand the logic behind the decision.
FSOs are leveraging data and artificial intelligence to create scalable and automated solutions — but at the same time they are also scaling their reputational, regulatory and legal risks. AI stimulates unprecedented business gains, but along the way, government and industry leaders have to address a variety of ethical challenges and dilemmas such as machine learning bias, data privacy issues, robustness, interpretability and explainability of AI-tools and overall transparency to create complete trust in the adoption of AI technologies.
To follow their strategies in developing, and implementing AI technologies, organizations should consider establishing AI ethics frameworks and guidelines. There is existing law and regulation adapting to address AI, alongside the implementation of new, standalone, AI regulation. There are legal, ethical and reputational risks that FSOs face when using AI. As well as the legal risks, FSOs need to focus on managing the ethical issues of AI. The public debate is now on how companies should behave, rather than simply complying with the law. A challenge for global companies is to identify a consistent set of ethical standards and values, across multiple jurisdictions where there may be cultural variations, in circumstances where the capabilities of the AI are constantly evolving.
What is Ethical AI?
Within the past several years, the discussion of Ethical AI has shifted from an academic concern to a matter of both political and public debate. Even though the concept of ‘machine ethics’ was proposed around 2006, Ethical AI is still in the infancy stage and is a complex and intricate concept. What exactly is Ethical AI, and what is it trying to accomplish?
Ethical AI, a branch of the ethics of technology specific to AI systems, is concerned with the important question of how human developers, manufacturers and operators should behave in order to minimize the ethical harms that can arise from AI in society, either arising from unethical design, inappropriate application or misuse. Ethical AI is part of the ethics of advanced technology that focuses on robots and other AI systems and agents. The concept studies the ethical principles, rules, guidelines, policies, and regulations that are related to AI. Moreover, Ethical AI is a set of values, principles, and techniques that employ widely accepted standards to guide moral conduct in the development and use of AI technologies. Broadly speaking, ethics as it related to AI can be defined as the discipline dealing with the moral obligations and duties of entities (e.g., humans, intelligent robots, agents, etc.).
Just a few years ago, discussions of ‘AI ethics’ were reserved for nonprofit organizations and academics. Today the biggest tech companies in the world are putting together fast-growing teams to tackle the ethical problems that arise from the widespread aggregation, analysis, and use of massive volumes of data, particularly when that data is used to train machine learning models which is a sub-field of AI.

Figure 1
AI ethics is not simply about ‘virtue or vice’. It is not even a problem that can be solved by a small group of people. Companies are investing in answers to ethical questions because they’ve realized one simple truth: failing to operationalize data and AI ethics is a threat to the bottom line. Failing to achieve the mark can expose companies to reputational, regulatory, and legal risks, but that’s not the half of it. Failing to operationalize AI ethics leads to wasted resources, inefficiencies in analytics development and deployment, and even an inability to use data to train AI models at all. In other words, the success of AI ethics lies in the ethical quality of its prediction, the ethical quality of the products and the ethical quality of the impact it has on humans.
The scope of AI ethics spans over immediate concerns such as bias, data privacy and transparency in AI systems; medium-term concern like impact of AI on economics, jobs and society; and long-term concern about the possibility of AI systems reaching superintelligence. AI ethics introduces three major areas of ethical concerns for organizations:
- Privacy and data governance
- Bias and fairness
- Transparency
- Robustness and safety
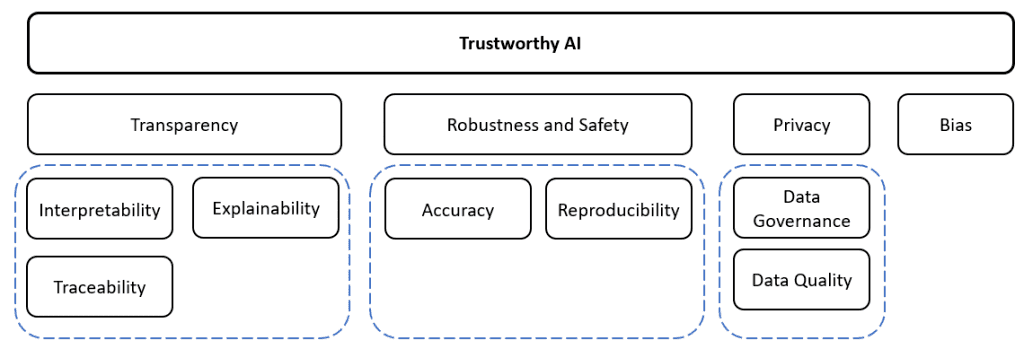
Figure 2: Framework for Trustworthy Artificial Intelligence
Fundamentals of Ethical AI
Privacy and Data Governance
Privacy and data governance are closely linked to the principle of prevention of harm to privacy, and are a fundamental right particularly affected by AI systems. Prevention of harm to privacy also necessitates adequate data governance that covers the quality and integrity of the data used, its relevance in light of the domain in which the AI systems will be deployed, its access protocols and the capability to process data in a manner that protects privacy.
- Privacy and data protection. AI systems must guarantee privacy and data protection throughout a ecosystems’ entire lifecycle. This includes the information initially provided by the user, as well as the information generated about the user over the course of their interaction with the system (e.g. outputs that AI system generated for specific users or how users responded to particular recommendations). Digital records of human behavior may allow AI systems to infer not only individuals’ preferences, but also their sexual orientation, age, gender, religious or political views. To allow individuals to trust the data gathering process, it must be ensured that data collected about them will not be used to unlawfully or unfairly discriminate against them.
- Quality and integrity of data. The quality of the data sets used is paramount to the performance of AI systems. When data is gathered, it may contain socially constructed biases, inaccuracies, errors and mistakes. This needs to be addressed prior to training any dataset. Furthermore, the integrity of the data must be ensured. Feeding low quality data into an AI system may change its behavior, particularly with self-learning systems. Processes and data sets used must be tested and documented at each step such as planning, training, testing and deployment. This should also apply to AI systems that were not developed in-house but which were acquired from third-parties.
- Access to data. In any given organization that handles individuals’ data (whether someone is a user of the system or not), data protocols governing data access should be put in place. These protocols should outline who can access data and under which circumstances. Only proper qualified personnel with the competence and need to access individual’s data should be allowed to do so.
Bias and Fairness
Data Bias
AI-based systems have significant economic advantages and opportunities, but there are limitations around how much can be done with them if it is difficult to understand how they work. For example, in consumer lending there are concerns across the industry around the biases a system could preserve; any data that has been collected previously could be intentionally or unintentionally biased. For example, an Natural Language Program (NLP) models were used to predict the next words in sentences or passages. Because it had been trained in Wikipedia data, it was making correlations between ‘man’ and ‘scientist’, ‘woman’ and ‘housewife’. “The model picked up on the bias that was already inside the text of Wikipedia. Therefore, algorithms can be used as an assisting hand but, ultimately, a human should be there to make the final decision. Part of the solution to eliminate bias lies in omitting specific variables and creating an inclusive dataset, which ensures that everyone is represented.
Data and Algorithmic Fairness
Additionally, data-driven technologies achieve accuracy and efficacy by building inferences from datasets that record complex social and historical patterns, which themselves may contain culturally crystallized forms of bias and discrimination. There is no silver bullet when it comes to remediating the dangers of discrimination and unfairness in AI systems. The problem of fairness and bias mitigation in architecting algorithms model and use therefore has no simple or strictly technical solution. That being said, best practices of fairness-aware design and implementation (both at the level of nontechnical self-assessment and at the level of technical controls and means of evaluation) hold great promise in terms of securing just, morally acceptable, and beneficial outcomes that treat affected parties fairly and equitably.
Responsible data acquisition, handling, and management is a necessary component of algorithmic fairness. If the results of AI project are generated by biased, compromised, or skewed datasets, affected parties will not adequately be protected from discriminatory harm. The project team should keep in mind the following key elements of data fairness:
- Representativeness: Depending on the context, either underrepresentation or overrepresentation of disadvantaged or legally protected groups in the data sample may lead to the systematic disadvantaging of vulnerable parties in the outcomes of the trained model. To avoid such kinds of sampling bias, domain expertise will be crucial to assess the fit between the data collected or acquired and the underlying population to be modelled. Technical team members should, if possible, offer means of remediation to correct for representational flaws in the sampling.
- Fit-for-Purpose and Sufficiency: An important question to consider in the data collection and acquirement process is, will the amount of data collected be sufficient for the intended purpose of the project? The quantity of data collected or acquired has a significant impact on the accuracy and reasonableness of the outputs of a trained model. A data sample not large enough to represent with sufficient richness the significant or qualifying attributes of the members of a population to be classified may lead to unfair outcomes. Insufficient datasets may not equitably reflect the qualities that should rationally be weighed in producing a justified outcome that is consistent with the desired purpose of the AI system. Members of the project team with technical and policy competencies should collaborate to determine if the data quantity is, in this respect, sufficient and fit-for-purpose.
- Source Integrity and Measurement Accuracy: Effective bias mitigation begins at the very beginning of data extraction and collection processes. Both the sources and tools of measurement may introduce discriminatory factors into a dataset. When incorporated as inputs in the training data, biased prior human decisions and judgments — such as prejudiced scoring, ranking, interview-data or evaluation—will become the ‘ground truth’ of the model and replicate the bias in the outputs of the system. In order to secure discriminatory non-harm, the data sample has to have an optimal source integrity. This involves securing or confirming that the data gathering processes involved suitable, reliable, and impartial sources of measurement and robust methods of collection.
- Timeliness and Recency: If the datasets include outdated data, then changes in the underlying data distribution may adversely affect the generalizability of trained model. Provided these distributional drifts reflect changing social relationship or group dynamics, this loss of accuracy with regard to the actual characteristics of the underlying population may introduce bias into AI system. In preventing discriminatory outcomes, timeliness and recency of all elements of the dataset should be scrutinized.
- Relevance, Appropriateness and Domain Knowledge: The understanding and utilization of the most appropriate sources and types of data are crucial for building a robust and unbiased AI system. Solid domain knowledge of the underlying population distribution and of the predictive goal of the project is instrumental for selecting optimally relevant measurement inputs that contribute to the reasonable resolution of the defined solution. Domain experts should collaborate closely with data science teams to assist in the determination of the optimally appropriate categories and sources of measurement.
Outcome Fairness
As part of this minimum protection of discriminatory non-harm, well-informed data, consideration must be put into how to define and measure the fairness of the impacts and outcomes of the AI system. There is a great diversity of beliefs in the area of outcome fairness as to how to properly classify what makes the consequences of models supported decision equitable and fair. Different approaches and principles are being incorporated: some focus on demographic parity, some on individual fairness, others on error rates equitably distributed across subpopulations.
The determination of outcome fairness should heavily depend both on the specific use case for which the fairness of outcome is being considered and the technical feasibility of incorporating selected criteria into the structure of the AI system. It means that determining fairness definition should be a cooperative and multidisciplinary effort across the project team. Various fairness methods involve numerous types of technical types of technical approaches at the pre-processing, modelling, or postprocessing stages of production. These technical approaches have limited scope in terms of the bigger picture issues of algorithmic fairness that we have already stressed.
Many of the formal approaches work only in use cases that have distributive or allocative consequences. In order to carry out group comparisons, these approaches require access to data about sensitive/protected attributes (that may often be unavailable or unreliable) as well as accurate demographic information about the underlying population distribution.
Transparency
Transparency is an essential requirement for generating trust and AI adoption. Meanwhile, regulatory compliance and model security also require companies to design a certain level of explainability, interpretability into models, and encompasses transparency of elements relevant to an AI system: the data, the models, and the system. Transparent AI enables humans to understand what is happening in AI black box. This means that it’s all about why and how AI decides something. AI transparency would help users recognize when an AI decision isn’t correct.
Interpretability and Explainability
In the context of Machine Learning (ML) and transparent AI, explainability and interpretability are often used interchangeably. While they are very closely related, it’s worth differentiate between these two notions.
Interpretability is the extent to which a cause and effect can be observed within a system. Or, to put it another way, it is the extent to which you are able to predict what is going to happen, given a change in input or algorithmic parameters. It’s being able to look at an algorithm and clearly identify exactly what is happening.
Explainability, meanwhile, is the extent to which the internal mechanics of a machine or deep learning system can be explained in human terms. It’s easy to miss the subtle difference with interpretability, but consider it like this: interpretability is about being able to discern the mechanics without necessarily knowing why. Explainability is being able to quite literally explain what is happening.
The central problem with both explainability and interpretability is that by adding an additional step in the development process, in fact, multiple steps are added. From one perspective, this looks like there is an attempt to tackle complexity with even greater complexity.
Transparency as a principle of AI ethics encompasses the following meanings:
- On the one hand, transparent AI involves the interpretability of a given AI system, i.e. the ability to know how and why a model performed the way it did in a specific context and therefore to understand the rationale behind its decision or behavior. This sort of transparency is often referred to ‘opening the black box’ of AI. It involves content clarification and intelligibility or explicability.
- On the other hand, transparent AI involves the explainability that allow humans see whether the models have been thoroughly tested and make sense, and that they can understand why particular decisions are made
There are three critical tasks for designing and implementing transparent AI.
- Task of Process Transparency: In offering an explanation to affected stakeholders, there is a need to demonstrate that considerations of ethical lawfulness, non-discrimination and public trustworthiness were operative end-to-end in the design and implementation processes that lead to an automated decision or behavior. This task will be supported both by following the best practices outlined below throughout the AI project lifecycle and by putting into place robust auditability measures through an accountability-by-design framework.
- Task of Outcome Transparency: In offering an explanation to affected stakeholders, it is necessary to clarify the content and explain outcomes by showing in plain language that is understandable to non-specialists how and why a model performed the way it did in a specific decision-making or behavioral context. Therefore, it is vital to clarify and communicate the rationale behind its decision or behavior. This explanation should be socially meaningful in the sense that the terms and logic of the explanation should not simply reproduce the formal characteristics or the technical meanings and rationale of the statistical model but should rather be translated into the everyday language of human practices and therefore be understandable in terms of factors and relationships that the decision or behavior implicates.
- Task of Outcome Transparency: Providing explanation of ethical legal, non-discriminatory generated decision made by the system to affected parties. It should take the content from outcome transparency and weight that explanation against the adhered criteria to throughout the design and use pipeline: ethical legal, non-discriminant, fair and trustworthiness. Exploit an optimal approach to process transparency from the start should support and safeguard this demand for normative explanation and outcome justification.
Technical Robustness and Prevention of Harm
A crucial component of achieving trustworthy AI is technical robustness, which is closely linked to the principle of prevention of harm. Technical robustness requires that AI systems be developed with a preventative approach to risks and in a manner such that they reliably behave as intended while minimizing unintentional and unexpected harm, and preventing unacceptable harm.
- Resilience to attack and security. AI systems should be protected against vulnerabilities that can allow them to be exploited by adversaries. Attacks may target the data and cause data poisoning or the underlying infrastructure, both software and hardware. If an AI system is attacked, e.g., in adversarial attacks, the data as well as system behavior can be changed, leading the system to make different decisions, or causing it to shut down altogether. For AI systems to be considered secure, possible unintended applications of the AI system and potential abuse of the system by malicious actors should be taken into consideration, and steps should be taken to prevent and mitigate these.
- Accuracy. Accuracy is one way to measure how AI system’s ability to make correct classifications, for example to correctly classify information into the proper labels, or its ability to make correct predictions, recommendations, or decisions based on data or models. An explicit and well-formed development and evaluation process can support, mitigate and correct unintended risks from inaccurate predictions. When occasional inaccurate predictions cannot be avoided, it is important that the system can indicate how likely these errors are. A high level of accuracy is especially crucial in situations where the AI system directly affects human lives.
- Reliability and Reproducibility. It is critical that the results of AI systems are reproducible, as well as reliable. A reliable AI system is one that works properly with a range of inputs and in a range of situations. This is needed to scrutinize an AI system and to prevent unintended harms. Reproducibility describes the ability to implement, as exactly as possible, the experimental and computational procedures, with the same data and tools, to obtain the same results as in an original work. In other words, it exhibits the same behavior when repeated under the same conditions. This enables scientists and policy makers to accurately describe what AI systems do.
- Robustness. The objective of robustness can be thought of as the goal that an AI system functions reliably and accurately under harsh conditions. These conditions may include adversarial intervention, implementer error, or skewed goal-execution by an automated learner in Reinforcement Learning (RL) paradigm. The measure of robustness is therefore the strength of a system’s integrity and the soundness of its operation in response to difficult conditions, adversarial attacks, perturbations, data poisoning, and undesirable reinforcement learning behavior.
Minimize the Risk of AI with NICE Actimize
Responsible AI in Financial Crime Risk Management
At NICE Actimize, we recognize several indicative components for mitigating AI risks and making connections between the principles and guidelines embodied in AI ethics and ongoing discussions within the Actimize scientific community. To obtain the capabilities of mitigating risks in your analytical solutions and AI-decision making systems, we recommend to focus on the following root-based methodologies and best practices:
- To provide objective views on the current landscape of AI, focusing on the aspects of bias, privacy, transparency and robustness. This include a technical discussions of risks associated with AI in terms of data bias, data privacy, model explainability and interpretability. As well, embedding AI in risk management framework.
- To present the scientific solutions that are currently under active development in the AI community to mitigate risks.
- To put forward a list of recommendations presenting policy-related consideration for the attention of the regulation and model governance to establish a set of standards and certification tools for AI systems.
Several avenues for reflection should be considered to attempt the implementation of standards in AI technologies, as well as of AI components embedded in NICE Actimize’s products and services. These avenues include:
- Introducing standardized methodologies to assess the trustworthy of AI models, in particular to determine their field of action with respect to the data that have been used for the training, the type of statistical model, or the context of use, amongst others factors;
- Raising awareness among NICE Actimize’s AI community through the publication of good practices regarding to known vulnerabilities of AI models and technical solutions to address them;
- Promoting transparency in the conception of machine learning models, emphasizing the need of an explainability-by-design approach for AI systems with potential negative impacts on fundamental rights of users
Understanding and addressing ethical and moral issues related to AI is still in the infancy stage. AI ethics is not simply about ‘good or bad’, and ‘virtue and vice’. It is not even a problem that can be solved by a small group of people.
Ethical and moral issues related to AI are critical and need to be discussed now. Financial services organizations need to make sense of these systems in terms of the consequential roles that their decisions and behaviors play in that human reality. The social context of these outcomes matters greatly because they actually affect individuals and society in direct and morally consequential ways, and the outcomes need to be understood and explained not just in terms of their statistical logic, technical rationale, and social context but also in terms of the justifiability of their disparate impact on people.
Delving more deeply into the technical and delivery aspects of trustworthy AI shows how these concepts and principles directly line up with the different levels of demand for these type of systems. When considering how to make the outcomes of decision-making and problem-solving AI systems fully transparent to affected parties, the multi-dimensional view of human reasoning should be taken into account because it more effectively addresses the spectrum of concerns that all parties may have.
References
- Abiteboul, S. et.al., (2015). Data, Responsibly. ACM Sigmod Blog.
- ACM US Public Policy Council. (2017). Statement on algorithmic transparency and accountability.
- Adadi, A., et. al., (2018). Peeking inside the black-box: A survey on Explainable Artificial Intelligence (XAI). IEEE Access, 6, 52138-52160.
- Agarwal, A., et. al., (2018). A reductions approach to fair classification.
- AI Now Institute. (2018). Algorithmic Impact Assessments: Toward Accountable Automation in Public Agencies.
- Alexander, V., et.al., (2018). Why trust an algorithm? Computers in Human Behavior, 89, 279-288
- Amodei, D., et.al., (2016). Concrete problems in AI safety.
- Bell, D. et.al., Scaling up: digital data services for the social sciences. UK Data Service.
- Bibal, A., et.al., (2016). Interpretability of Machine Learning Models and Representations: an Introduction.
- Bracamonte, V. (2019). Challenges for transparent and trustworthy machine learning. KDDI Research, Inc.
- Calo, R. (2017). Artificial Intelligence policy: a primer and roadmap. UCDL Rev., 51, 399.
- Card, D. (2017). The “black box” metaphor in machine learning. Towards Data Science.
- Chen, J. et.al., (2014). Situation awareness-based agent transparency. Aberdeen Proving Ground, MD: U.S. Army Research Laboratory
- Fong, R. C., et. al., (2017). Interpretable explanations of black boxes by meaningful perturbation. In Proceedings of the IEEE International Conference on Computer Vision (pp. 3429-3437).
- Google. (2019). Perspectives on issues in AI governance
- Hamon Ronan et.al., (2020). Robustness and Explainability of Artificial Intelligence.
- John Jay College of Criminal Justice (2017), Ethics and Bias in ML: A Technical Study of What Makes Us “Good”.
- Journal of Database Management (2020). AI Ethics
- Kemper, J., et.al., (2018). Transparent to whom? No algorithmic accountability without a critical audience. Information, Communication & Society, 1-16.
- Kemper, J., et.al., (2018). Transparent to whom? No algorithmic accountability without a critical audience. Information, Communication & Society, 1-16.
- Keng Siau (2018). Ethical and Moral Issues with AI
- Morley, J., et.al., (2019). From what to how. An overview of AI ethics tools, methods and research to translate principles into practices.
- Murdoch, W., et. al., (2019). Interpretable machine learning: definitions, methods, and applications.
- Nicola Fabiano (2019). Ethics and Protection of Personal Data
- Pedreschi, D., et. al., (2019). Meaningful explanations of black box AI decision systems. AAAI Press.
- Samuel Lo Piano (2020), Ethical Principles in Machine Learning and AI.
- Schaefer, K. et.al., (2016). A meta-analysis of factors influencing the development of trust in automation: Implications for understanding autonomy in future systems. Human factors, 58(3), 377-400.
- The Harvard Gazette (2020). Promise and Potential Pitfalls of the Rising age of AI and Machine Learning.
- Thilo Hagendorff (2020). The Ethics of AI Ethics.
- Varshney, K. et.al., (2017). On the safety of machine learning: Cyber-physical systems, decision sciences, and data products. Big Data, 5(3), 246-255.
- Verma, S., et.al., (2018). Fairness definitions explained.
- Von Wright, G. H. (2004). Explanation and understanding. Ithaca, NY: Cornell University Press.
- Walton, D. (2004). A new dialectical theory of explanation. Philosophical Explorations, 7(1), 71-89.
- Zhang, J., et. al., (2018). Fairness in decision-making the causal explanation formula. Presented at the 32nd AAAI.